본 문서는 Introduction Python 책을 공부하면서 정리한 내용입니다.
3.1 리스트와 튜플
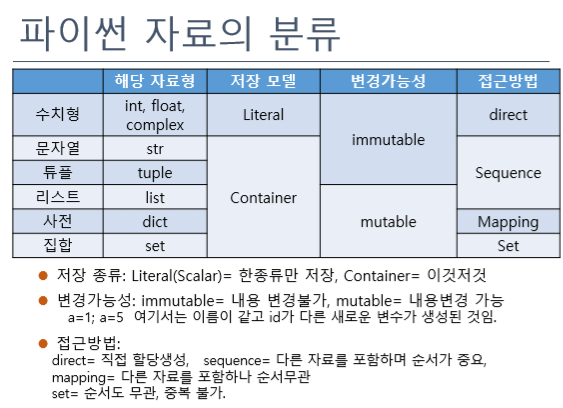
다른 자료를 포함하고 순서가 중요한 시퀀스 구조엔 튜플과 리스트가 있다. 튜플은 불변이고 리스트는 변경가능하다.
3.2 리스트
리스트 생성하기 : [] 또는 list()
다른 데이터 타입을 리스트로 변환하기
In [1]: a_tuple = ('ready','fire')
In [2]: list(a_tuple)
Out[2]: ['ready', 'fire']
offset으로 항목 얻기
리스트와 리스트
offset으로 항목 바꾸기
슬라이스로 항목 추출하기
In [3]: marxes = ['Groucho','Chico','Harpo']
In [4]: marxes[0:2]
Out[4]: ['Groucho', 'Chico']
In [5]: marxes[::2]
Out[5]: ['Groucho', 'Harpo']
리스트의 끝에 항목 추가하기 : append()
리스트 병합하기 : extend() / +=
In [7]: marxes = ['Groucho','Chico','Harpo']
In [8]: others = ['Gummo','Karl']
In [9]: marxes.extend(others)
In [10]: marxes
Out[10]: ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Karl']
In [11]: marxes += others
In [12]: marxes
Out[12]: ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Karl', 'Gummo', 'Karl']
오프셋과 insert()로 항목 추가하기
insert() 함수는 원하는 위치에 항목을 추가 할 수 있다.
오프셋으로 항목 삭제 : del
del은 파이썬 구문이다. 객체의 메모리를 비워준다.
In [12]: marxes
Out[12]: ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Karl', 'Gummo', 'Karl']
In [13]: del marxes[-1]
In [14]: marxes
Out[14]: ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Karl', 'Gummo']
값으로 항목 삭제하기 : remove()
삭제할 항목 위치 모르는 경우, remove()와 값으로 항목 삭제 가능
In [14]: marxes
Out[14]: ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Karl', 'Gummo']
In [15]: marxes.remove('Gummo')
In [16]: marxes
Out[16]: ['Groucho', 'Chico', 'Harpo', 'Karl', 'Gummo']
오프셋으로 항목을 얻은 후 삭제하기 : pop()
값으로 항목 오프셋 찾기 : index()
In [16]: marxes
Out[16]: ['Groucho', 'Chico', 'Harpo', 'Karl', 'Gummo']
In [17]: marxes.index('Harpo')
Out[17]: 2
존재여부 확인 : in
값 세기 : count()
문자열 변환하기 : join()
join()의 인자는 문자열 혹은 반복 가능한 문자열 시퀀스다. 반환값은 문자열이다.
In [18]: ', '.join(marxes)
Out[18]: 'Groucho, Chico, Harpo, Karl, Gummo'
정렬하기 : sort()
- sort() : 리스트 자체를 내부적으로 정렬
- sorted() : 리스트의 정렬된 복사본을 반환
In [19]: sorted_marxes = sorted(marxes)
In [20]: sorted_marxes
Out[20]: ['Chico', 'Groucho', 'Gummo', 'Harpo', 'Karl']
In [21]: number = [2,1,4.0,3]
In [22]: number.sort(reverse=True)
In [23]: number
Out[23]: [4.0, 3, 2, 1]
항목 개수 얻기 : len()
할당 = / 복사 copy()
할당의 경우 한 리스트를 변경하면 다른 리스트도 변경된다. 그러나 복사는 원본리스트에 아무런 영향을 주지 못한다.
In [24]: a = [1,2,3]
In [25]: b = a.copy()
In [26]: c = list(a)
In [27]: d = a[:]
In [28]: b
Out[28]: [1, 2, 3]
In [29]: c
Out[29]: [1, 2, 3]
In [30]: d
Out[30]: [1, 2, 3]
3.3 튜플
튜플 생성하기:()
- 두개 이상 요소가 있을 경우, 마지막 요소에 콤마를 붙이지 않는다.
In [31]: marx_tuple = 'Grouch','Chico','Harpo'
# 좀 더 나은 표기법
In [33]: marx_tuple = ('Grouch','Chico','Harpo')
In [32]: marx_tuple
Out[32]: ('Grouch', 'Chico', 'Harpo')
- 튜플 언패킹
In [34]: a,b,c = marx_tuple
In [35]: a
Out[35]: 'Grouch'
In [36]: b
Out[36]: 'Chico'
In [37]: c
Out[37]: 'Harpo'
- 값 교환
In [38]: password = 'swordfish'
In [39]: icecream = 'tuttifrutti'
In [40]: passwrod, icecream = icecream, password
In [41]: passwrod
Out[41]: 'tuttifrutti'
In [42]: icecream
Out[42]: 'swordfish'
튜플과 리스트
튜플을 사용하는 이유
- 더 적은 공간을 사용
- 실수로 튜플의 항목이 손상될 염려가 없다.
- 튜플을 딕셔너리 키로 사용
- 네임드 튜플의 객체의 단순한 대안 가능
- 함수의 인자들을 튜플로 전달
3.4 딕셔너리
리스트와 다른 점은 항목의 순서를 따르지 않으며, 값에 상응하는 고유 키를 가지고 있다.
딕셔너리 생성하기 :{}
딕셔너리로 변환하기 : dict()
# 리스트 -> 딕셔너리
In [43]: lol = [ ['a','b'],['c','d'],['e','f']]
In [44]: dict(lol)
Out[44]: {'a': 'b', 'c': 'd', 'e': 'f'}
# 튜플로 된 리스트 -> 딕셔너리
In [47]: lot = [('a','b'),('c','d'),('e','f')]
In [48]: dict(lot)
Out[48]: {'a': 'b', 'c': 'd', 'e': 'f'}
# 리스트로 된 튜플
In [49]: tol = (['a','b'],['c','d'],['e','f'])
In [50]: dict(tol)
Out[50]: {'a': 'b', 'c': 'd', 'e': 'f'}
# 문자열로 된 리스트
In [51]: los = ['ab','cd','ef']
In [52]: dict(los)
Out[52]: {'a': 'b', 'c': 'd', 'e': 'f'}
항목 추가/변경하기 : [key]
키가 딕셔너리에 이미 존재하는 경우, 새값으로 대체된다. 키가 존재하지 않은 경우 추가된다. 또한 키들은 반드시 유일해야 한다.
딕셔너리 결합하기 : update()
딕셔너리의 키와 값들을 복사해서 다른 딕셔너리에 붙여준다.
두번째 딕셔너리를 첫번째 딕셔너리에 병합하려고 하면, 두 딕셔너리에 같은 키 값이 있는 경우, 두번째 딕셔너리에 있는 값으로 대체된다.
In [55]: first = {'a':1,'b':2}
In [56]: second = {'b':'platypus'}
In [57]: first.update(second)
In [58]: first
Out[58]: {'a': 1, 'b': 'platypus'}
키와 del로 항목 삭제하기
모든 항목 삭제하기 : clear()
키와 값을 모두 삭제하기 위해서 사용한다. 또 빈 딕셔너리를 이름에 할당해도 된다.
in으로 키 멤버십 테스트하기
항목 얻기 : [key]
In [59]: pythons = {'Chapman':'Graham', 'Cleese':'John','Jones':'Terry'}
In [60]: pythons['Cleese']
Out[60]: 'John'
In [61]: pythons.get('Marx','Not a Pytnon')
Out[61]: 'Not a Pytnon'
모든 키 얻기 : keys()
파이썬3는 순회 가능한 키들을 보여주는 dict_keys()를 반환한다. 아주 큰 딕셔너리에 유용하다. 사용되지 않을 리스트를 생성하고 저장하기 위한 메모리와 시간을 소비하지 않기 때문
In [65]: pythons = {'Chapman':'Graham', 'Cleese':'John','Jones':'Terry'}
In [66]: pythons.keys()
Out[66]: dict_keys(['Chapman', 'Cleese', 'Jones'])
모든 값 얻기 : values()
모든 쌍의 키-값 얻기 : items()
각 키와 값은 튜플로 반환된다.
In [67]: list(pythons.items())
Out[67]: [('Chapman', 'Graham'), ('Cleese', 'John'), ('Jones', 'Terry')]
할당 = / 복사 copy()
3.5 셋
셋은 값만 버리고 키만 남은 딕셔너리와 같다. 딕셔너리와 마찬가지로 각 키는 유일해야 하고 어떤것이 존재하는지 여부만 판단하기 위해 셋을 사용한다.
셋 생성하기 : set()
데이터 타입 변환하기 : set()
리스트, 문자열, 튜플, 딕셔너리로부터 중복한 값을 버린 셋을 생성 가능하다.
딕셔너리의 경우 set()을 사용하면 키만 사용한다.
In [69]: set({'apple':'red','orange':'ornage','cherry':'red'})
Out[69]: {'apple', 'cherry', 'orange'}
in으로 값 멤버십 테스트하기
In [70]: drinks = {
...: 'martini':{'vodka','vermouth'},
...: 'black russian':{'vodka','kahlua'},
...: 'white russian':{'cream','kahlua','vodka'},
...: 'manhattan':{'rye','vermouth','bitters'},
...: 'screwdriver':{'orange juice','vodka'}
...: }
In [71]: for name,contents in drinks.items():
...: if 'vodka' in contents:
...: print(name)
martini
black russian
white russian
screwdriver
콤비네이션과 연산자
- & / intersection() : 교집합
In [74]: a = {1,2}
In [75]: b = {2,3}
In [76]: a.intersection(b)
Out[76]: {2}
- | / uncion () : 합집합
In [78]: a.union(b) Out[78]: {1, 2, 3} - ㅡ / difference : 차집합
In [79]: a.difference(b) Out[79]: {1} - ^ / symmetric_difference() : 대칭 차집합 , 한쪽 셋에는 들어 있지만 양쪽 모두에 들어 있지 않은 멤버
In [80]: a.symmetric_difference(b) Out[80]: {1, 3} - <= : 서브셋 (부분집합)
- < : 프로퍼 서브셋(진부분집합) , 두번째 셋에는 첫번째 셋의 모든 멤버를 포함한 그 이상의 멤버가 있어야 한다.
- superset() : 프로퍼 슈퍼셋 , 첫번재 셋에는 두번째 셋의 모든 멤버를 포함한 그 이상의 멤버가 있어야 한다.
요약