크롤링 구현 부분
- 어려웠던 점
- url파악하기
- axa 형식 가져오는 것
- 크롤링 파씽
검색 리스트 도서 크롤링
사용자가 검색하고자 하는 도서명을 입력하면 그에 따른 도서 리스트를 출력하는 크롤링함수다. 검색조건의 경우 처음엔 도서명,출판사,저자 이런순으로 입력을 받게끔 했다. 예를 들어 생능출판사 컴퓨터구조론을 찾을 려면컴퓨터구조론,생능, 이렇게 입력 받게 했다.
그러나 트러블슈팅을 통해 사용자가 좀더 쉽게 사용할 수 있는 방안이 필요하다는 것을 알게되었다. 결과적으로 도서명검색과 상세검색 기능으로 분리했다. 왜냐하면 기본적으로 도서명으로 검색하되, 전공서적의 경우 도서명만 찾으면 너무 많은 도서들이 있기 때문에 필요하다고 생각했기 때문이다.
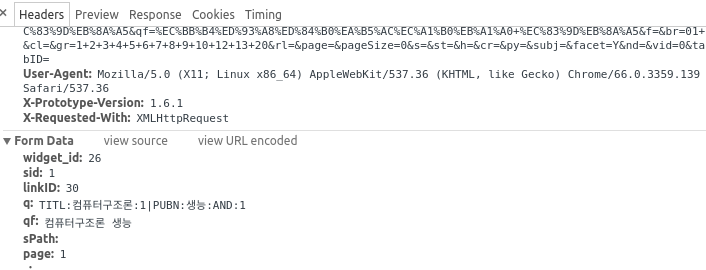 그리고 크롤링만들면서 url parameter 때문에 조금 힘들었다. 직접 url을 만드는 경우 어떤 요소인지 알지만, 학교 사이트 경우 어떤걸 나타내는 파악하기 어려웠고, 검색어 이외에도 추가되는 parameter가 있엇기 때문에 예외적인 사항들이 많았다. 그래도 크롬 개발자 툴을 사용해서 Header 를 분석하고 postman으로 요청을 보내면서 url과 param를 만들었다.
(기특한 개발자모드!!)
그리고 크롤링만들면서 url parameter 때문에 조금 힘들었다. 직접 url을 만드는 경우 어떤 요소인지 알지만, 학교 사이트 경우 어떤걸 나타내는 파악하기 어려웠고, 검색어 이외에도 추가되는 parameter가 있엇기 때문에 예외적인 사항들이 많았다. 그래도 크롬 개발자 툴을 사용해서 Header 를 분석하고 postman으로 요청을 보내면서 url과 param를 만들었다.
(기특한 개발자모드!!)
검색 keyword 생성 함수
도서명검색과 상세검색 이렇게 두가지로 나눠졌기 때문에 키워드를 url에 맞게끔 만드는 함수도 2개로 분리했다.
def search_book_title(search):
"""
제목을 통한 도서 검색 키워드 생성
:param search:
:return:
"""
keyword = 'TITL:' + search
return books_crawler(keyword)
def search_book_detail(search):
"""
사용자가 search('제목,출판사,저자')를 입력하면 항목에 따라
keyword를 생성후 크롤링 함수 실행
:param search:
:return: search에 입력한 책 정보 출력
"""
keyword = ''
search_list = search.split(',')
if search_list[0] is not '':
keyword = 'TITL:' + search_list[0]
if search_list[1] is not '':
keyword = keyword + "|" + "PUBN:" + search_list[1]
if search_list[2] is not '':
keyword = keyword + "|" + "AUTH:" + search_list[2]
return books_crawler(keyword)
도서 대출 여부 및 위치
크롤링을 하면서 가장 힘들었던 건 도서 위치를 가져오는 것이었다. 도서 위치와 관련된 정보는 javascript 함수로 실행되는 것 같았다. 즉 이 부분을 크롤링하는 것이 불가능했다. 처음엔 도서위치를 빼고 대출 여부만 결과값으로 출력했으나 서비스를 사용하는 주된 목적이 아마도 도서위치를 사서에게 물어보지 않고 알고 싶을 것이라는 주변의 피드백을 통해 여러 가지 시도를 통해 결국 이 정보를 가져올 수 있게 되었다.
그러나 해당 URL의 경우 x-www-form-urlencoded방식으로 요청을 보내야만 했다.(이걸 알아내는 대도 한참이 걸렸다….)
x-www-form-urlencoded 란?
참고
application/x-www-form-urlencoded: &으로 분리되고, “=” 기호로 값과 키를 연결하는 key-value tuple로 인코딩 값이다. 영어 알파벳이 아닌 문자들은 percent encoded 으로 인코딩된다. 따라서, 이 content type은 바이너리 데이터에 사용하기에는 적절치 않다. (바이너리 데이터에는 use application/form-data 를 사용)
def book_location_crawling(book_id, book_info):
"""
도서 위치 및 대출 정보를 크롤링하는 함수
:param book_id:
:return: 서가위치, 도서번호, 대출여부
"""
post_format = {
'cid': book_id,
}
r = requests.post('http://library.sejong.ac.kr/search/ItemDetailSimple.axa', data=post_format)
test = BeautifulSoup(r.content, 'html.parser')
tbody = test.find('tbody').find_all('tr')
books_list = list()
Django command arguments
프로젝트를 진행하면서 import 문제로 크롤링 모듈이 제대로 작동되지 않았던 일이 있었다. source root보다 밑에서 크롤링 함수가 작동되기 때문에 다른 모듈들을 가져오지 못했던 것이다.
다른 모듈들을 제대로 import 시키고 작동시키기 위해 custom django-admin commands를 만들었다.
management/commands 생성하기
install_apps 에 등록된 앱에 management/command패키지를 생성하고 ./manage.py를 통해 실행시킬 commands 명령어 이름으로 파일을 생성한다.(ex, ./manage.py crawling)
.
├── app
│ ├── books
│ │ ├── admin.py
│ │ ├── apps.py
│ │ ├── __init__.py
│ │ ├── management
│ │ │ ├── commands
│ │ │ │ ├── crawling.py
│ │ │ │ ├── __init__.py
command/crawling.py
참고자료_ django 공식 문서
참고자료_설명
command에서 실행시킬 명령어 동작을 정의해보자. 나의 경우엔 크롤링을 실행할때 매개변수를 넘겨줘야 한다.
from django.core.management import BaseCommand
from books.utils import search_book
class Command(BaseCommand):
def add_arguments(self, parser):
# 메서드에 인자 추가
parser.add_argument('keyword', nargs='+', )
def handle(self, *args, **options):
# 커맨드 로직을 처리
keyword = options['keyword'].pop()
result, url = search_book(keyword)
return result
nargs: 파라미터가 받을 수 있는 값의 개수를 의미한다. - N : n개의 값을 받을 수 있다. - ? : 값이 없을 경우 defult 값을 넘겨준다. - */ + : 여러개의 값을 받을 수 있다.- return 값의 경우 string으로 반환한다.
해결해야하는 문제
- 카카오톡 메시지 보내는 부분에 글자수 제한이 있어 텍스트가 일부 잘린다. ex) 컴퓨터
- 고전독서와 같이 동일 제목으로 여러권의 책이 있을 경우 너무 많은 정보가 출력된다.ex) 황금가지
- 현재 검색 후 1페이지만 크롤링을 해오는데 더 많은 페이지를 크롤링해야 하는가에 대한 의문